一文搞懂Python进程、线程、协程选择
TL;DR
if io_bound:
if io_very_slow:
print("use asyncio")
else:
print("use multithread")
else:
print("use multiprocess")
关于线程、进程、协程的常见问题
linux中线程和进程的区别?
对于linux来说,实际上没有区别,一组线程(>=1)就是一个进程1,而在python主流解释器实现(CPython)中,进程和线程最大区别之一就是,多进程不受GIL的影响,而一个进程中的多个线程的运行(一个进程中的多个线程能在不同的cpu上运行)则受GIL的影响,所以多进程(使用合理的进程数量)理论上是最快的。
官方GIL解释:assure that only one thread executes Python bytecode at a time.
先从简单的情况说起,当前讨论范围是单核CPU,某一时刻只能运行一个线程。
def blocking_io():
# File operations (such as logging) can block the
# event loop: run them in a thread pool.
with open('/dev/urandom', 'rb') as f:
return f.read(100)
def cpu_bound():
# CPU-bound operations will block the event loop:
# in general it is preferable to run them in a
# process pool.
return sum(i * i for i in range(10 ** 7))
什么时候需要多线程?
多线程适合I/O密集型的任务,例如需要执行n次blocking_io,假设执行方法所需时间为t,只有一个进程的话,就是串行执行,运行时间为n*t。
而对于多线程的情况,虽然同一时间只能有一个线程在执行,在第一个线程在待等待io时候,可以切换到第二个线程执行,当第二个线程在等待io的时候,…诸如此类。总的运行时间只有t+线程切换的时间(相对较小)。
举个例子: I/O密集型(程序等待IO的时间不少)的任务可以类比为点外卖,假设这个过程分为三部分(下单+外卖员配送+取外卖),单进程就是你下单取到第一个外卖之后再下单第二个外卖。如果是多线程的话就是,你下单完第一个外卖之后就下单第二个外卖。
而对于CPU密集型的任务,例如需要执行n次cpu_bound,多线程并不适合,因为没有空闲的时间可以利用,切换进程只会增加总的运行时间。这时候需要多核cpu,同一时间能够运行多个线程。
什么时候需要协程?
协程切换的开销很小,且花费的内存小,在任务I/O耗时较长的且较多的时候,协程的性能一定比线程要好,具体看后面的测试结果。
什么时候需要进程和线程结合使用?
当任务即使I/O密集型也是CPU密集型的时候,这种情况可以分为两大类,一种是CPU操作依赖I/O操作的结果,另一种是I/O操作依赖CPU操作的结果。对于这两种情况,经本地测试,都适合在进程池里面使用线程池。
实战分析
来自于工作中碰到的简化场景,具体来说是单机每秒发出1k的rpc请求。这里把rpc请求替换为文件的io操作,分别使用进程池、线程池、协程池的方式处理任务。
i/o密集型任务
1k任务总量
####asyncio thread pool
0.9911940097808838
####asyncio process pool]
1.2635221481323242
####thread pool
1.2167432308197021
####process pool
1.5319018363952637
10k任务总量
####asyncio thread pool
5.968851804733276
####asyncio process pool]
6.5089499950408936
####thread pool
7.458053112030029
####process pool
6.667386054992676
可以看到使用线程池性能略好,和使用进程池的差别并不大。因为本质上python的进程、线程和操作系统是一致的,而慢了一些的原因,我猜测是python中的进程调度有一些附加的操作。
cpu密集型任务
1k任务总量
####asyncio thread pool
0.8021156787872314
####asyncio process pool]
0.5527217388153076
####thread pool
0.7702062129974365
####process pool
0.4566621780395508
10k任务总量
####asyncio thread pool
7.525069952011108
####asyncio process pool]
3.0321288108825684
####thread pool
7.162564277648926
####process pool
1.6991519927978516
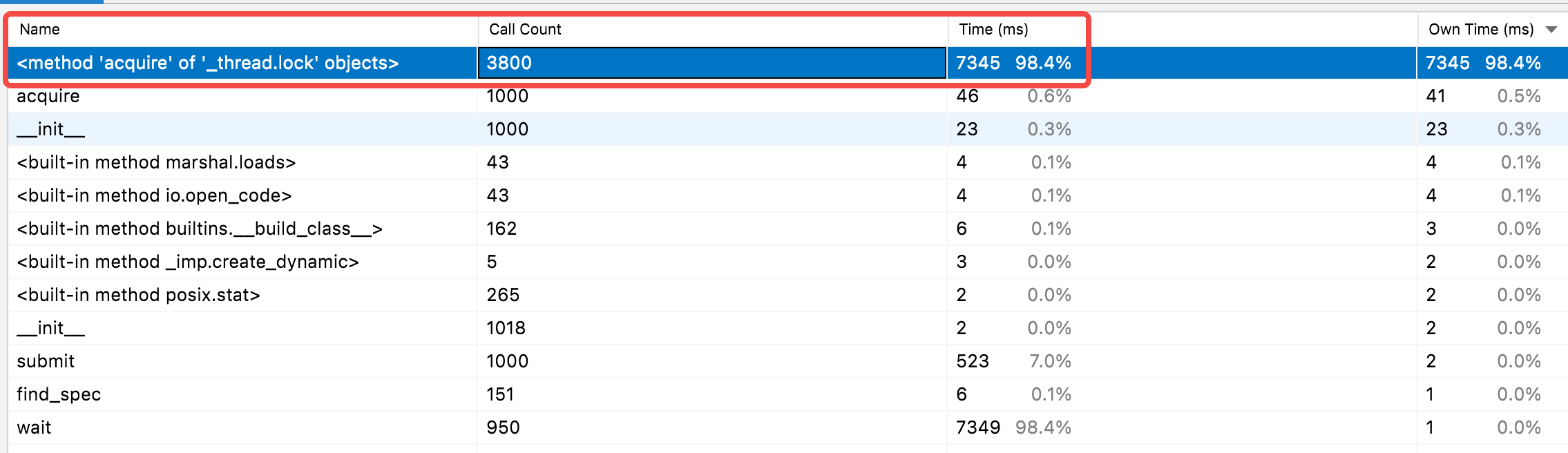
前面提到,由于GIL的原因,某一时刻只能有一个线程在运行,其他线程会阻塞在GIL锁,抢锁的次数会非常多。可以通过PyCharm的profile查看耗时较多的函数,这里只profile一下使用线程池的函数。
i/o、cpu密集型任务
1K任务总量
####asyncio process pool, using thread pool True
0.8400530815124512
####asyncio process pool, using thread pool False
1.1249358654022217
####process pool, and using threading pool True
0.8603811264038086
####process pool, and using threading pool False
0.9869413375854492
10k任务总量
####asyncio process pool, using thread pool True
6.82210898399353
####asyncio process pool, using thread pool False
11.561522960662842
####process pool, and using threading pool True
9.900066614151001
####process pool, and using threading pool False
11.04285192489624
测试代码:
import asyncio
import time
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor, wait
from multiprocessing import Pool
total = 1000
def task():
# io密集型
# with open('/dev/urandom', 'rb') as f:
# return f.read(100)
# cpu密集型
return sum(i * i for i in range(10 ** 5))
async def async_with_thread():
executor = ThreadPoolExecutor()
loop = asyncio.get_event_loop()
t1 = time.time()
tt = [loop.run_in_executor(executor, task) for _ in range(total)]
await asyncio.wait(tt)
t2 = time.time()
print("####asyncio thread pool")
print(t2 - t1)
async def async_with_process():
t = total
executor = ProcessPoolExecutor()
loop = asyncio.get_event_loop()
t1 = time.time()
tt = [loop.run_in_executor(executor, task) for _ in range(total)]
await asyncio.wait(tt)
t2 = time.time()
print("####asyncio process pool]")
print(t2 - t1)
def thread_pool():
executor = ThreadPoolExecutor()
t1 = time.time()
futures = [executor.submit(task) for _ in range(total)]
wait(futures)
t2 = time.time()
print("####thread pool")
print(t2 - t1)
def process_pool():
p = Pool()
t1 = time.time()
for _ in range(total):
p.apply_async(task)
p.close()
p.join()
t2 = time.time()
print("####process pool")
print(t2 - t1)
if __name__ == '__main__':
asyncio.run(async_with_thread())
asyncio.run(async_with_process())
thread_pool()
process_pool()
import asyncio
import time
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor, wait
from multiprocessing import Pool
total = 10000
def _task_cpu():
return sum(i * i for i in range(10 ** 4))
def _task_io():
with open('/dev/urandom', 'rb') as f:
return f.read(100)
def _task_both_cpu_feed_io(use_thread_pool):
if use_thread_pool:
executor = ThreadPoolExecutor(max_workers=1)
futures = [executor.submit(_task_io)]
wait(futures)
else:
_task_io()
return _task_cpu()
task = _task_both_cpu_feed_io
async def async_with_process(flag):
executor = ProcessPoolExecutor()
loop = asyncio.get_event_loop()
t1 = time.time()
tt = [loop.run_in_executor(executor, task, flag) for _ in range(total)]
await asyncio.wait(tt)
t2 = time.time()
print("####asyncio process pool, using thread pool %s"%flag)
print(t2 - t1)
def process_pool(flag):
p = Pool()
t1 = time.time()
for _ in range(total):
p.apply_async(task, args=(flag,))
p.close()
p.join()
t2 = time.time()
print("####process pool, and using threading pool %s"%flag)
print(t2 - t1)
if __name__ == '__main__':
asyncio.run(async_with_process(True))
asyncio.run(async_with_process(False))
process_pool(True)
process_pool(False)
参考
- Multithreading VS Multiprocessing in Python
- Difference between a “coroutine” and a “thread”?
- asyncio.loop.run_in_executor in python doc
- Python Multiprocessing combined with Multithreading
- Understanding the Python GIL